For six months the industry has been attacking the same villain: tokenmaxxing — treating token consumption as if it were an achievement. A Fortune 500 CEO called it a vanity metric. A major cloud company killed an internal leaderboard over it. The verdict is unanimous: counting tokens is the new counting lines of code. Easy to measure, easy to game, uncorrelated with what actually matters.
We've gotten good at rejecting the wrong metric. We haven't agreed on the right one.
Here it is
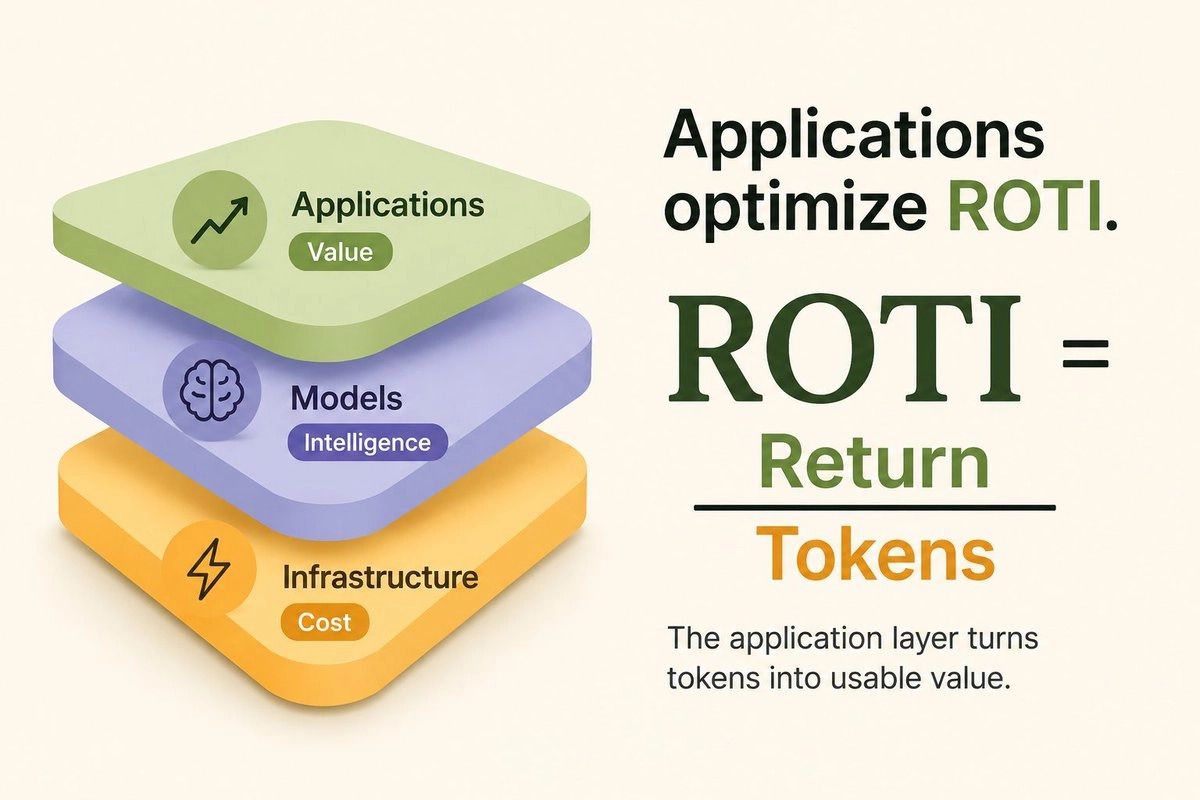
| ROTI — Return on Token Investment. The value you get, divided by the tokens spent to get it.
Tokenmaxxing puts tokens in the numerator and calls a bigger number progress. ROTI puts them where they belong: in the denominator. Tokens are the cost of a result, not the result itself — investment, not achievement.
Each layer of the stack optimizes for something different.
- Infrastructure optimizes for cheaper tokens — turning energy into output.
- Models optimize for more capable tokens — more intelligence per unit.
- The application layer, the one closest to you, optimizes for ROTI — turning tokens into value you can actually use.
That last job is the one the layer quietly skipped, because until agents arrived, nobody felt the bill.
Why now?
For three years AI felt like a gym membership — flat fee, unlimited use, a human typing every prompt and judging every answer. The meter was throttled by human effort.
Agents broke that. An agent can burn 5,000,000 tokens on a task you described in 12 words — planning, calling tools, retrying, looping — while you watch nothing. And the bill is now visible: one developer's monthly cost went from ~$29 to nearly $750. Another, from $50 to ~$3,000. People are calling it "meter shock," and the most common reaction is brutal: it's cheaper to rent a server myself.
The worst part: spend doesn't track value. Jellyfish found top-decile developers burned ~10x the tokens per merged PR — for roughly 2x the output.

The real problem isn't memory. It's compounding
Most AI now remembers facts (you like bullet points) but doesn't compound work. It re-discovers the same context, rebuilds the same workflow, repeats the same mistakes — and every one of those re-'s is metered now.
That's not compounding intelligence. That's rented intelligence — paid by the session, returned at the end, re-rented tomorrow at full price. Rented intelligence has terrible ROTI by definition: every task starts from zero, so every task costs full freight.
The fix
An agent that remembers how to do the work. Context, workflows, tool paths, skills — all carrying forward. The first run is full price. The tenth should be a fraction of it, and better. That's the only honest answer to meter shock: not a cheaper meter, but a meter that runs less every week.
The first wave of AI taught us to spend tokens. The next will help us compound them.

This is the thesis we're building AllyHub around — an agent where every task it finishes makes the next one cheaper and sharper. Not an assistant you re-teach each morning. One that compounds.